
Case Study:
SBB Cargo
The Challenge
The silo problem
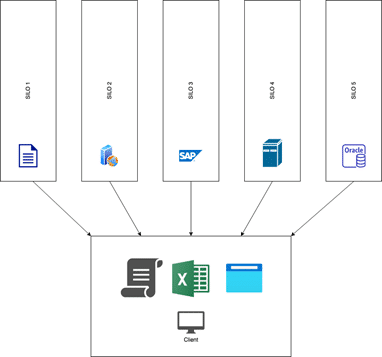
In modern businesses, data is ubiquitous and comes from a wide array of different sources like:
- Company website(s)
- Company app(s)
- IoT devices
- CRMs
- Social Media
- Inventories & logistics tools (like SAP)
- Data warehouses
- Internal reports
- Sales channels
- You name it
The main problem of such a scenario is that each of those data are saved into so called «vertical siloes» and those siloes aren’t designed to allow cross-siloes data sharing.
This root problem, generates many other issues:
- trying to analyze those data with aggregation tools and transversally across siloes requires a lot of error-prone and tedious handwork, involving data exporting, data extraction, spreadsheet «mambo-jambos»: in few years, companies end up with a set of handcrafted tools.
- Such handcrafted tools are quite fragile and heavily dependent on who implemented it originally, making them a nightmare to be maintained.
- When it comes to data, it’s not clear what the «single source of truth is».
- It’s even more unclear where data reside, especially in mid-large organizations.
- Raw (unmodified) data are often missing.
The following diagram summarize the silo architecture.
The Solution
The data lake
A way to solve the «vertical siloes» problem is to build a data lake. It’s a place where data, coming from different sources, can be stored and accessed in a consistent way. Data are stored in theirs natural/raw format, making possible future data manipulation. Sometime transformed data are stored in data lake also; they are necessary for tasks such as reporting, visualization, advanced analytics, and machine learning.
Usually data «lineage» (where data comes from, when it was acquired and manipulated and by whom/what) is saved together with datasets (as metadata or using some easy-to-search way).
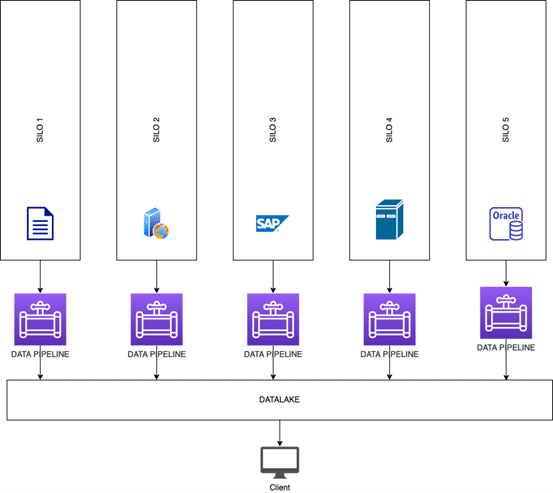
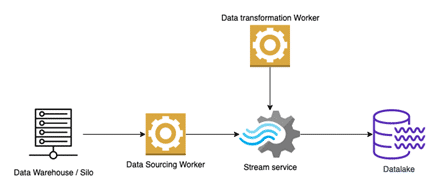
What is a data pipeline?
To «hydrate» a data lake, workers that acquire data from sources (siloes) need to be provisioned. Each worker is specific for a data source and is attached to services that allow further near-real-time data analysis. This set of functionalities (worker + services) is commonly referred as «data pipelines«. In analogy to water pumps and pipes, data are extracted («pumped») from sources and «flow» through services until they land in data lakes or specific storage/database solutions.
The following picture exemplifies these concepts.
Going serverless
Building a data lake and hydrating data pipelines can be achieved using:
a) On-prem services
b) Cloud based self-managed services
c) Cloud based fully managed services
d) Cloud based serverless infrastructure
The level of commitment required to operate the previous architectures significally decreases from a) to d).
On a) all the ops work is on IT team, including hardware management.
On d) the only things that the IT team must focus on are:
- application logic development (Worker logic);
- using the right tools for the job and use their API, following proper security best practices.
Since data lakes involve a lot of moving part and different technologies, going fully serverless is a choice worth to be considered to reduce operational complexity.
Tools & Technologies
Implementation on AWS
AWS is all about choices, so there are services to build each of the architectures mentioned before. Customers can go from fully on-prem (renting bare metal machines) to fully serverless event-driven infrastructure. And even in a serverless scenario there are several options to choose from.
What follows is an implementation that we’ve developed for one of our key customers and that is running in production.
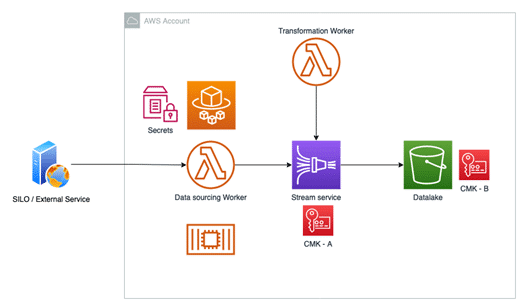
The services used in this implementation are:
- AWS Lambda as computing infrastructure to run data sourcing worker and transformation worker
- AWS Kinesis stream / Firehose as data stream service provider
- Amazon S3 as data lake storage system
- AWS KMS as encryption service
- AWS System Manager Parameter Store as repository for secrets
- AWS IAM for policy / roles definition
Let’s go briefly on each component to analyze the logic behind the architectural choices.
- Data Sourcing Worker => AWS Lambda:
This worker needs to connect to the silo/ service and to extract data from it. According to the type of data and its usage, this worker could run few times per day or continuously. In a serverless environment on AWS, the choices are:
-
- Lambda (scheduled execution)
- A container deployed on ECS using Fargate as computing infrastructure (continuous execution)
We’ve opted for Lambda because customer desired to have a data pipeline architecture able to deal with different data frequency; for nearly continuous data flows, a short invocation rate coupled with small datasets per execution provides a good solution to use a simple Lambda function instead of a more complicated containerized worker, keeping also architectural consistency with discrete data flows.
- Transformation Worker => AWS Lambda:
This worker transforms data according to specific criteria, which depend on the actual data source. Lambda is the recommended solution to be used together with AWS Kinesis Firehose. An input event is generated from Kinesis with raw sourced data, Lambda process and transform data according to the logic implemented by code and the transformed data is sent back to Kinesis Firehose for that can be persisted. - Stream Service => Kinesis Stream / Firehose:
Streams are particularly useful in data ingestion because they buffer input data for a configurable period and enable a pluggable architecture to consume, analyze and process data, in batch and/or near real-time. Kinesis Firehose is a serverless managed data stream service, whose purpose is to dump data continuously to a specific target type. In this specific case, the target is a S3 bucket. Like Kinesis Stream, Firehose can generate events attaching data flowing in it. Those events can be used to execute code through Lambda or to trigger complex tasks using AWS Step-Functions or other AWS services. - Data lake => Amazon S3:
Infinite storage capacity, configurable lifecycle policies and custom metadata are perfect to build a data lake. Amazon S3 offers that, together with a powerful API and a seamless integration with other AWS services, like Firehose. The data lake may consist in a single bucket or in multiple ones (raw data, transformed data, aggregated data…) - Security 1 => KMS:
Data in transit and at rest are encrypted using KMS with scope limited CMKs (Customer Master Keys) - Security 2 => Lambda specific role & policies:
Lambda functions run using scoped-down permissions, expressed through IAM policy documents attached to a specific role which is assigned to the lambda. - Security 3 => Secrets:
To store secrets and service wide parameters, Parameter Store is used. Secrets are saved as secure-strings and encrypted with KMS using a dedicated CMK
Results & Benefits
Benefit 1
Benefit 2
Standardizing architecture with templates helps tremendously with multi-region failover.
Benefit 3
Using serverless and fully decoupled stateless services also makes them scalable out-of-the-box.
Conclusion
Data lakes are the key for freeing data and making them available across multiple users and standard tools.
They are also quite challenging to be correctly implemented from scratch, as they require cloud expertise and good development skills. Having the right partner in this phase helps and speeds up the process a lot. Major cloud providers like AWS provide a huge set of tools and services to make the transition from data-siloes to data ubiquity much easier and operationally sustainable in the long term. We proved that with our customer, where a fully remote pizza-box size team developed and deployed to production multiple data-pipelines, making data widely accessible to business and operational units. In 2021 there are less excuses to not introduce data-lakes and automated data ingestion through data-pipelines in company data strategy.
written by

Kunde
SBB Cargo
SBB Cargo is a subsidiary of Swiss Federal Railways (SBB) specialising in railfreight and is operated as the Freight division. The headquarters of Swiss Federal Railways SBB Cargo AG, the Freight division’s official designation, are in Olten. In 2013, SBB Cargo had 3,061 employees and achieved consolidated sales of CHF 953 million.[1] In Switzerland, SBB Cargo is the market leader in rail freight, transporting over 175,000 tons of goods every day. This corresponds to the weight of 425 fully loaded jumbo jets.
Partner
AWS
As AWS Advanced Consulting and training partner, we support Swiss customers on their way to the cloud. Cloud-native technologies are part of our DNA. Since the company’s foundation (2011), we have been accompanying cloud projects, implementing and developing cloud-based solutions.











