
#knowledgesharing #level 100
How does data replication work??

With Nutanix Data Protection you can protect/replicate everything that is running in a Nutanix cluster, whether it is a VM, a Volume Group (only supported by Prism Element replication), or a File Share.
Depending on your business requirements, Nutanix can help you achieve this using multiple "flavors" (asynchronous or synchronous) that are available.
- Asynchronous replication
- Hypervisor agnostic
- Delay replication time 1h
- Near Sync
- Asynchronous replication from 1 min up to 15 mins
- Hypervisor agnostic
- Support only one to one replication
- Different technology used for Near Sync: Lightweight Snapshots (LWS).
- Synchronous replication – Metro availability
- Hypervisor agnostic
- Metro cluster configuration for VMWare
- 0ms replication delay
- Possible to automate failover using a Witness VM for ESXi and Prism Central for AHV
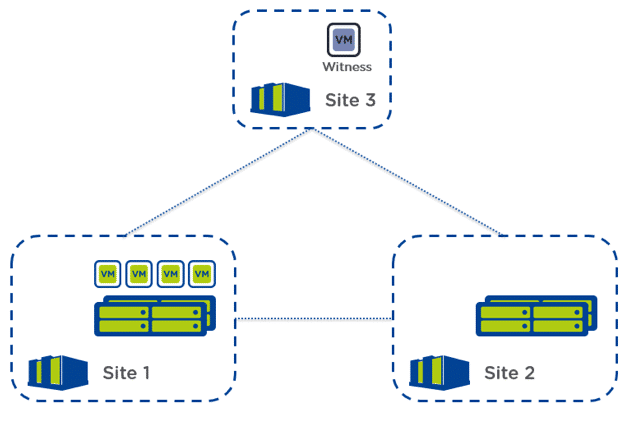
Nutanix's data protection is very granular and flexible at the topology level, and it allows you to configure different scenarios:
- Two-Way Mirroring (aka one to one)
That’s the most common protection strategy and consists of mirroring the infrastructure from site A to site B. It’s possible to configure a protection domain A (from A to B) and protection domain B (from B to A) to make both sites act active-passive, spread the workload, and avoid an outage on all the VMs as in case of issues, only 50% of the VMs would be affected and the rest runs intact.

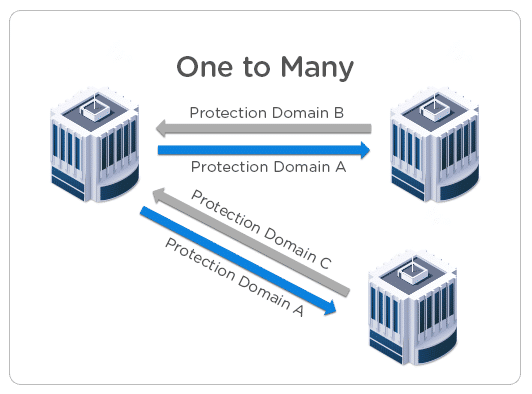
- One to Many
In this replication scenario, A is the main location there are multiple remote locations. The main workload is running on-site A and sites B and C (remote locations) act as backup for specific workloads.
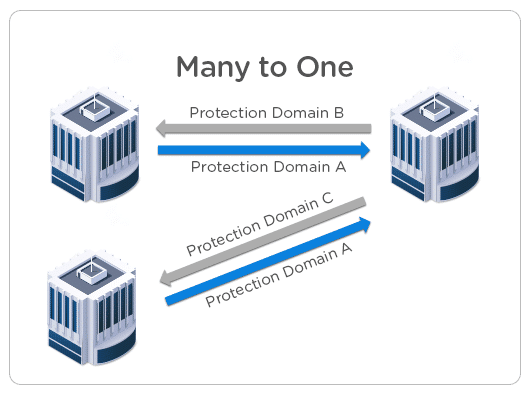
- Many to One
Imagine there are multiple branch offices, and all the data is backed up to a main central location. This is a classical example of ROBO data protection architecture where all the workload running on ROBO clusters is backed up to a main big cluster.
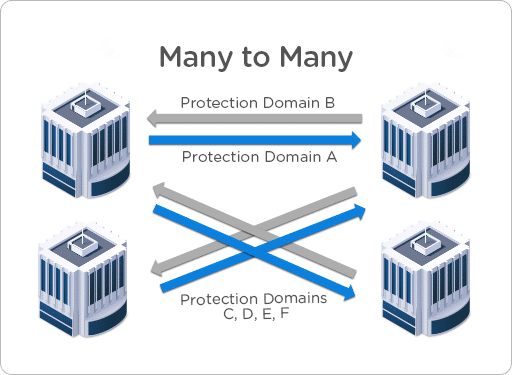
- Many to Many
That topology allows the most flexible setup. Using it you ensure the best application continuity and protection strategy.
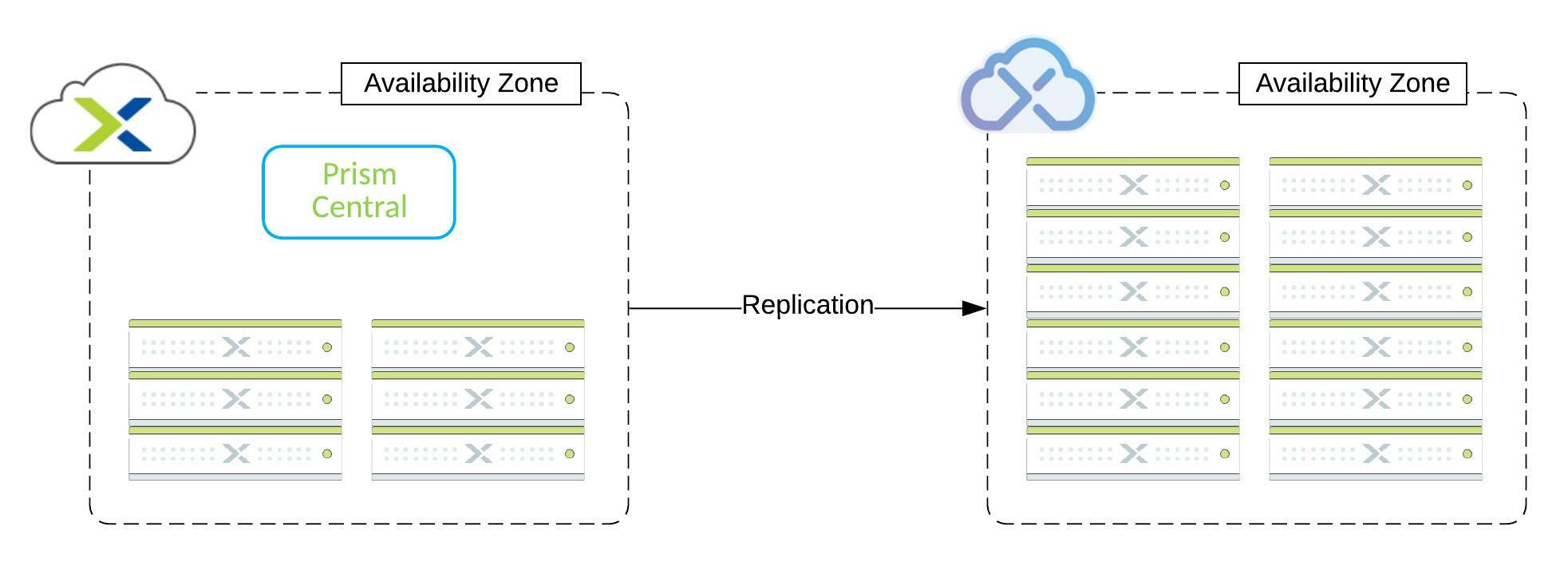
- Cloud as recovery site – Xi Leap
Nutanix offers the possibility to use its integrated cloud solution as a recovery site, Xi Leap. Xi Leap eliminates the need for a dedicated Disaster Recovery Site, and It’s managed by Prism Central. There are a few points to focus on:
- Availability Zones
- All Nutanix clusters connected to a Prism Central instance or Xi Leap Zone. Depending on the architecture, it can represent a DataCenter, server room, or geographic territory.
- Protection Policies
- Define the RPO (Recovery Point Objective), retention period.
- Categories
- Used to assign VMs to protection policies.
- Recovery Plans
- Englobe the specifications of the disaster recovery plan like VMs boot order, IP address management, and virtual networking mappings.
Xi Leap availability zones over the world:
- US West
- US East
- UK
- Germany
- Italy
- Japan
Xi Leap is “cross hypervisor” DR (from ESXi to AHV), minimum RPO is 1h, allows the customer to save money, rack space, cooling power, network switches ports as a secondary infrastructure, which is not used often, is not in place.
Conclusion
Nutanix data protection allows multiple topologies and replication setup choices to fit 100% of your business requirements. It is possible to combine all the options and create complex recovery scenarios to guarantee data persistence and availability.
Even is possible to configure the Cloud as a recovery site… Nutanix is cloud-friendly!!


