
#knowledgesharing #level 100
Machine Learning in der Praxis
Entgegen der öffentlichen Meinung beschäftigen sich viele Machine Learning Projekte nicht einfach mit dem «Trainieren» von einem Model auf korrekten oder inkorrekten Daten. Diese Meinung wird gerne von der Forschung vertreten, um Investoren für ihre Forschungsprojekte zu gewinnen. Ich versuche Ihnen meine Sichtweise der A.I. Projekte anhand von praxisorientierten Beispielen aus der Industrie und Privatwirtschaft zu verdeutlichen.
Machine Learning Projekte beschäftigen sich mit folgenden Fragestellungen:
- Die Anwendung eines allgemeinen Models
- Trainieren eines Models
- Komplizierte Problemstellungen
Die Anwendung eines allgemeinen Models wird dabei am meisten diskutiert, was uns viel über den tatsächlichen Bedarf in den Unternehmen verrät.
Fragestellung 1: Die Anwendung eines allgemeinen Models
Diese Fragestellung beschreibt die Anwendung von bereits bestehenden Produkten und Services wie bspw. AWS Rekognition für Computer Vision A.I. Um die Wichtigkeit dieser Kategorie zu erläutern, möchte ich einen kurzen Exkurs in das Mindset vieler Data Scientist machen: Das klingt herausfordernd und aufregend, jedoch wäre es naiv zu glauben, dass «mein Problem» das erste Mal durch mich gelöst wird. So hat es üblicherweise in der Informatik Produkte, Community Projekte, Cloud Services und vieles mehr, die ähnliche Herausforderungen lösen bzw. bereits gelöst haben. Wenn ein Webentwickler eine Webseite programmiert, verwendet er dazu viele bestehende Libraries, Vorlagen und Codesnippets… Warum sollte das bei Machine Learning anders sein?
Im Vergleich zu den selbst implementierten Modellen, handelt es sich bei allgemeinen ML-Produkten um robuste Services, welche durch das Feedback von Nutzern kontinuierlich verbessert werden. Zudem werden diese Produkte mit grossen Mengen an qualitativen Daten trainiert, was die Fehlerquote deutlich reduziert. Kein Unternehmen kann ein eigenes Model unter den genau gleich profitablen Bedingungen trainieren, denn meistens fehlt es den Unternehmen an bereinigten Daten, an der fehlenden Datenmenge oder an der altbekannten Schwarmintelligenz der Community. Durch die stetige Weiterentwicklung der zur Verfügung stehenden Modelle, wird die eigene Daten-Performance nachhaltig verbessert und gesteigert. Weshalb also das Rad neu erfinden und Risiken eingehen, wenn es dafür bereits anpassbare Vorlagen gibt?
Aus diesem Grund empfehle ich jedem Projektleiter, sich genau über bestehende Services zu erkundigen.
Als Beispiel könnte ein solches Projekt folgendermassen auf AWS aussehen: Der Prozess übermittelt ein Formular mit handschriftlichen Daten an die OCR-Lösung AWS Textract. Anschliessend werden die Daten ausgelesen. Die Daten werden mit Metadaten, Rechtschreibeüberprüfungen und weiteren Harmonisierungsalgorithmen nachträglich verbessert.
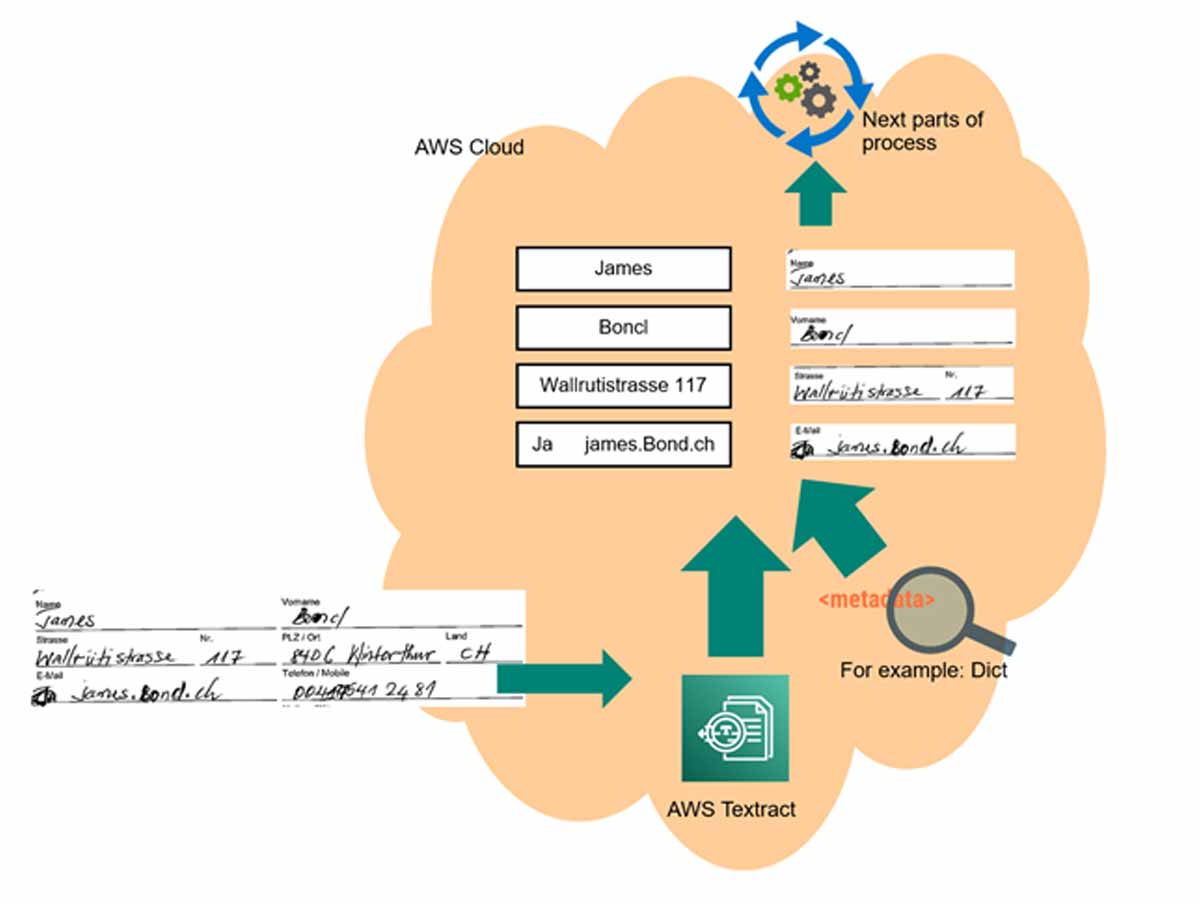
In der Grafik auf der rechten Seite, sehen sie ein Bild der eingelesenen Originaldaten in Handschrift. Auf der linken Seite wird die editierbare Inputbox dargestellt, die mit der AWS Textract Lösung erstellt wurde. Mit diesem Case möchte ich euch aufzeigen, wie mit Machine Learning wiederholende Mutationsarbeiten vereinfacht und schlussendlich die Effizienz eines Unternehmens gesteigert werden kann. Einlesen, statt abtippen!
Erfahrungsgemäss setzt sich ein solches Machine Learning Projekt aus den folgenden Aufgaben seitens Engineerings zusammen:
Fragestellung 2: Das Trainieren eines Models
Diese Fragestellung beschäftigt sich mit dem Aufbau eines Models mit eigenen Daten. Meine Ausführungen zum Thema “eigenes Model” habe ich im letzten Abschnitt erläutert. Es gibt zwei Ausnahmen, bei denen ein eigenes Model tatsächlich notwendig ist:
- Forschungsarbeiten, welche komplett neue Modelle entwickeln.
- Probleme, für die es keine allgemeinen Lösungen gibt oder allgemeine Daten stören würden. In diesem Fall eignet sich ein eigenes Model tatsächlich besser als die Arbeit mit einem bereits vorhandenen Produkt/Service.
Dennoch ist Vorsicht geboten: Man wird schnell dazu verleitet, dass man sein eigenes Problem als zu spezifisch sieht und gleich kopfüber in das Trainieren eines eigenen Models springen will. In 9 von 10 Fällen waren die mir gestellten Probleme nicht spezifisch genug, damit das Trainieren eines eigenen Modells gerechtfertigt wäre.
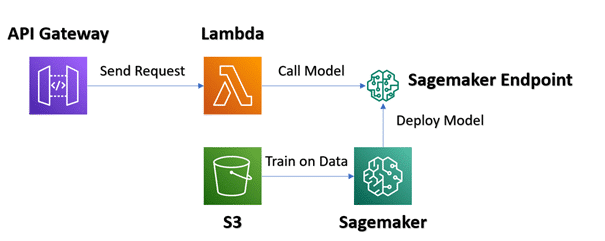
Ein Projekt aus der Praxis
Anhand des folgenden Beispiels zeige ich euch auf, wann eine Architektur «Trainieren eines Models» Sinn macht: Eine Stadt, mit untypischem Stromverbrauch im Vergleich zu anderen Städten, möchte eine Voraussage des Stromverbrauchs treffen.
In diesem Anwendungsbeispiel bietet API Gateway eine Rest-API an, worüber eine neue Voraussage erlangt werden kann. AWS Lambda führt Serverless den Sourcecode aus und erhält die Voraussage vom Sagemaker Endpoint. Sagemaker als Service ist eine auf Jupyter basierende Entwicklungsumgebung für das Trainieren von eigenen Machine Learning Modellen.
Erfahrungsgemäss setzt sich ein solches Machine Learning Projekt aus den folgenden Aufgaben seitens Engineerings zusammen:
Fragestellung 3: Die komplizierten Probleme
Ab wann ist ein Projekt nun als Machine Learning Projekt zu bezeichnen? Aus der Schulzeit mögen sich vielleicht noch einige an den Unterschied zwischen komplizierten und komplexen Problemen erinnern: Ein Problem ist kompliziert, wenn es zwar eine Herausforderung darstellt, dennoch mit Logik und nicht mit Approximationen gelöst werden kann. Sobald Approximationen und Methoden wie Machine Learning zum Einsatz kommen müssen, spricht man von komplexen Problemen. Deswegen sollte sich jeder Projektleiter oder Data Scientist zum Beginn eines Projektes fragen, ob ein Problem kompliziert oder komplex ist.
Mein beliebtestes Beispiel zur Darstellung eines komplizierten Problems, welches als Machine Learning Projekt startete, wird in der folgenden Architektur gezeigt, bei der ursprünglich der Einsatz von Computer Vision A.I. gewünscht war:
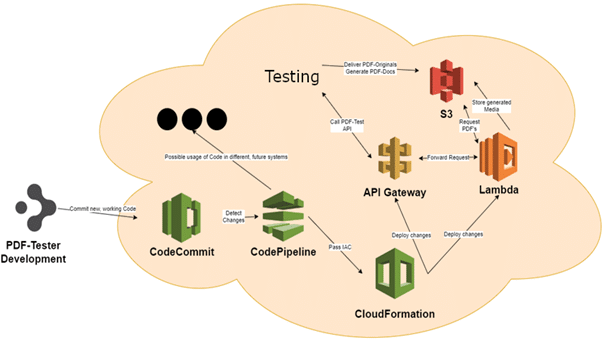
Hierbei handelt es sich um ein Testautomatisierungstool, bei welchem generierte PDF-Dokumente auf optische Unterschiede zum Basisstamm untersucht werden. Dabei wollte der Kunde den Einsatz von Computer Vision A.I., wodurch im besten Fall eine Genauigkeit von 99%, jedoch nie 100% erreicht wird.
Anstelle dieser Variante wurde mit der Lambdafunktion ein PDF-Mining-Tool entwickelt, das anhand von Metadaten des PDF’s alle Daten maschinell ausliest und vergleicht und somit eine Genauigkeit von 100% möglich wird.
Erfahrungsgemäss setzt sich ein solches Machine Learning Projekt aus den folgenden Aufgaben seitens Engineerings zusammen:


