

Cloud Engineer, aus Ostermundigen
#knowledgesharing #level 300
Nahezu Echtzeit-Dateneingabe in den SageMaker Feature Store
Das Ziel
Dieser Blog-Beitrag ist der erste Teil einer dreiteiligen Serie über den Test einer vollautomatischen MLOps-Pipeline für Machine-Learning-Vorhersagen auf zeitnahen Zeitreihendaten in AWS. Dieser Teil konzentriert sich auf die Data Ingestion Pipeline im Amazon SageMaker Feature Store.
Der gesamte Demo-Code ist im Projekt-Repository auf GitHub öffentlich verfügbar.
Sagemaker Feature Store
Wie in der Dokumentation beschrieben, haben wir uns für diese Demo dazu entschieden, den Amazon SageMaker Feature Store als endgültiges Repository für die Data Ingestion Pipeline zu verwenden.
"Amazon SageMaker Feature Store ist ein vollständig verwaltetes, zweckbestimmtes Repository zum Speichern, Freigeben und Verwalten von Funktionen für Modelle für maschinelles Lernen (ML). Merkmale sind Eingaben für ML-Modelle, die während des Trainings und der Inferenz verwendet werden."
Die Demo
Für die Demo werden Blockchain-Transaktionen von der blockchain.com-API (hier) verwendet. Basierend auf den eingelesenen Daten berechnet und speichert die Pipeline drei einfache Metriken im Amazon SageMaker Feature Store:
- Die Gesamtzahl der Transaktionen
- Der Gesamtbetrag der Transaktionsgebühren
- Die durchschnittliche Höhe der Transaktionsgebühren
Diese Metriken werden pro Minute errechnet. Auch wenn dieses Zeitfenster möglicherweise nicht optimal für die Analyse von Blockchain-Transaktionen ist, ermöglicht es uns dennoch, schnell eine Vielzahl von Datenpunkten zu sammeln. Auf diese Weise können wir die Laufzeit der Demo kurz halten und die damit verbundenen AWS-Kosten minimieren.
Diese Demo wurde mithilfe von AWS CDK entwickelt und ist hier verfügbar.
Die Architektur
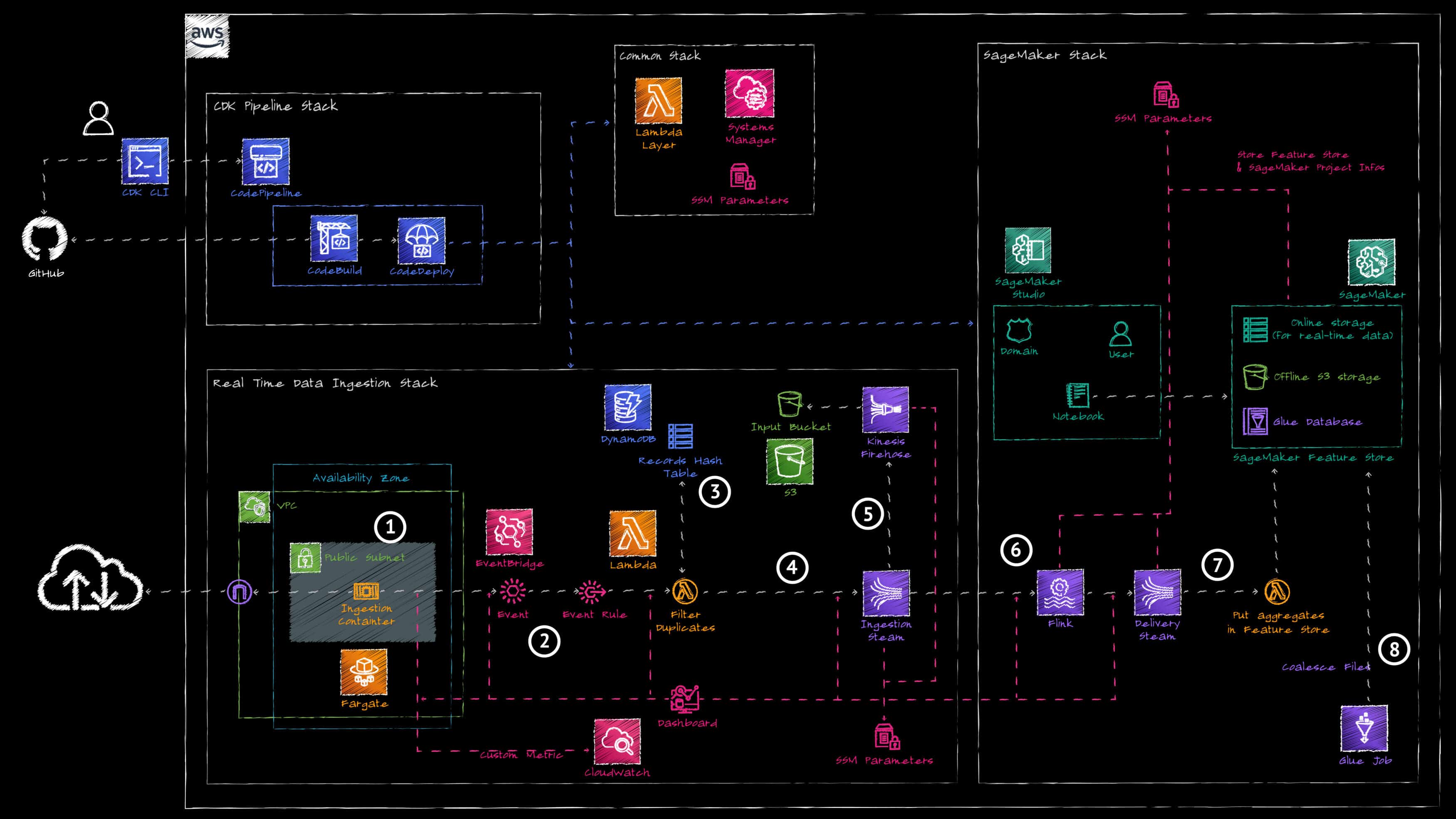
Das Projekt besteht aus einer sich selbst verändernden Pipeline, in der die verschiedenen Stacks des Projekts eingesetzt werden. Dabei werden nur die Komponenten der Data Ingestion Pipeline gezeigt. Der MLOps-Teil der Architektur wird in den folgenden Beiträgen näher erläutert.
Die Pipeline funktioniert wie folgt:
1. Ein AWS Fargate-Container fragt die Datenquellen-API alle 15 Sekunden ab, um die letzten 100 Transaktionen zu erfassen und alle Transaktionen auf dem Data Ingestion Event Bus von AWS EventBridge zu veröffentlichen.
2. Eine AWS EventBridge-Regel leitet die aufgenommenen Daten an eine AWS Lambda-Funktion weiter.
3. Die AWS Lambda-Funktion wird in Kombination mit Amazon DynamoDB verwendet, um die kürzlich aufgenommenen Transaktionen zu verfolgen und bereits aufgenommene Transaktionen herauszufiltern.
4. Die gefilterten Daten werden in einen Amazon Kinesis Data Stream geschrieben.
5. Der Ingestion Data Stream ist mit einem Amazon Kinesis Firehose Stream verbunden, der die Rohdaten zur Archivierung in einem Amazon S3 Bucket speichert.
6. Eine Amazon Managed Service for Apache Flink-Anwendung liest die Daten aus dem Ingestion-Stream und verwendet ein Tumbling-Fenster, um die folgenden 3 Metriken pro Minute zu berechnen:
a. Gesamtzahl der Transaktionen
b. Gesamtbetrag der Transaktionsgebühren
c. Durchschnittlicher Betrag der Transaktionsgebühren
6. Die Flink-Anwendung schreibt die aggregierten Daten in einen bereitgestellten Amazon Kinesis Data Stream. Eine AWS Lambda-Funktion liest aus dem Delivery Stream und schreibt die aggregierten Daten in den Amazon SageMaker Feature Store.
7. Ein AWS Glue Job aggregiert regelmässig die kleinen Dateien im Amazon SageMaker Feature Store S3 Bucket, um die Leistung beim Lesen der Daten zu verbessern.
Neben der Bereitstellung der Dateneingabepipeline stellt der Infrastruktur-Stack auch die Data Scientist-Umgebung mit Amazon SageMaker Studio bereit. Er erstellt eine Amazon SageMaker Studio-Domäne und legt darin einen Benutzer mit den entsprechenden Berechtigungen an. Damit hat der Data Scientist Zugriff auf eine IDE, in der er Jupyter Notebooks ausführen kann, um Analysen an den Daten vorzunehmen, Experimente durchzuführen und das Training eines Modells zu testen.
Wie kann man sich die eingehenden Daten ansehen?
Monitoring der Pipeline
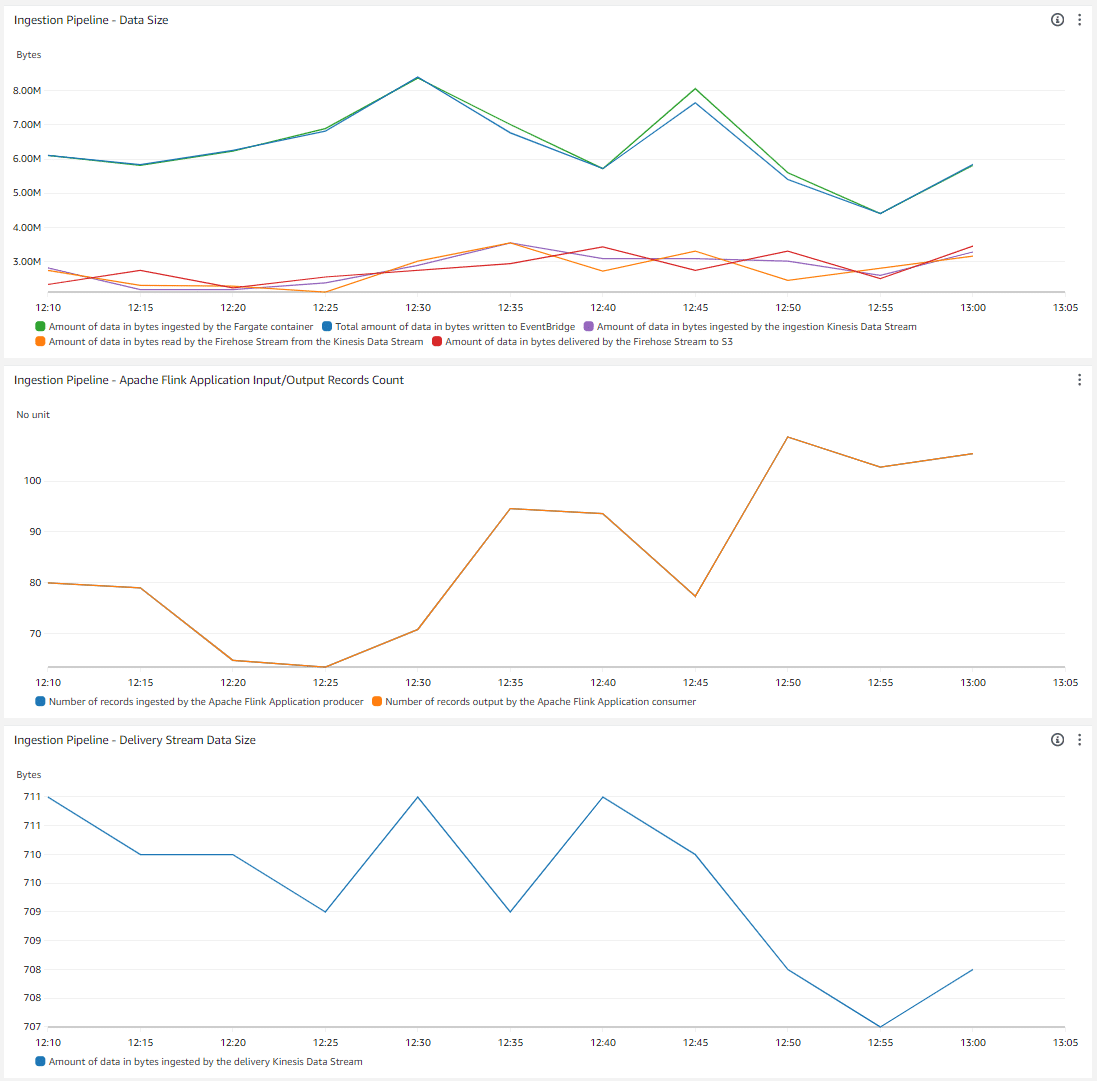
Die Demo enthält ein CloudWatch-Dashboard, mit dem du den Datenfluss durch die verschiedenen Komponenten verfolgen kannst. Im ersten Widget wird die Menge der Bytes angezeigt:
- Vom AWS Fargate-Container aufgenommene Daten
- Ingested by AWS EventBridge (Leider gibt es keine Metrik pro AWS EventBridge-Bus. Diese Metrik zeigt die Gesamtmenge der von EventBridge in das Konto aufgenommenen Daten)
- Vom Amazon Kinesis Data Stream Ingestion Stream aufgenommen
- Von Amazon Kinesis Firehose aus dem Ingestion Stream aufgenommen
- Übermittelt von Amazon Kinesis Firehose an Amazon S3
- Aufgenommen von Amazon Kinesis Analytics
Das zweite Widget zeigt die Anzahl der Datensätze an, die vom Apache Flink Application-Consumer ausgegeben und vom Apache Flink Application-Producer aufgenommen wurden (sollte gleich sein, wenn die Flink-Anwendung korrekt funktioniert). Das dritte Widget zeigt die Menge der vom Amazon Kinesis Data Stream Delivery Stream aufgenommenen Bytes an (1 Datensatz pro Minute).
Abfrage der Daten mit Amazon Athena
Mit Amazon Athena kannst du den Offline-Speicher des Amazon SageMaker Feature Store abfragen. Hier ist ein Abfragebeispiel (wenn du die Demo einsetzt, musst du den Tabellennamen des Feature Stores anpassen).

Abfrage der Daten mit Amazon SageMaker Studio Notebook
Im repository /resources/sagemaker/tests/ stellen wir ein Jupyter-Notebook read_feature_store.ipynb bereit, um den neuesten Eintrag im Online-Store zu lesen. In der Amazon SageMaker Studio-Domäne kannst du den bereitgestellten Benutzer verwenden und eine Studio-Anwendung starten. Sobald du dich in der Jupyter- oder Code-Editor-Umgebung befindest, kannst du das Notizbuch hochladen und ausführen. Dieses liest den letzten Datenpunkt aus dem Online Store des Amazon SageMaker Feature Store.
Du wirst einen Unterschied von ungefähr 6 Minuten zwischen dem Zeitstempel der letzten Daten im Online Store und im Offline Store des Amazon SageMaker Feature Store feststellen.
Die Herausforderungen
Die grösste Herausforderung bei der Entwicklung dieser Architektur mit CDK war die Bereinigung der SageMaker-Domäne. Beim Erstellen einer SageMaker-Domäne erstellt AWS eine Amazon EFS-Freigabe mit Endpunkten in der VPC und NSGs, die ihnen zugeordnet sind. Wenn ein Benutzer eine SageMaker Studio App startet, werden Rechenressourcen bereitgestellt, um die Code Editor/Jupyter IDE-Sitzung und die Jupyter-Kernel-Sitzung zu hosten. Keine dieser Ressourcen wird automatisch gelöscht, wenn die Domäne gelöscht wird. Das bedeutet, dass eine Custom Resource im CDK Stack entwickelt werden muss, um die Domäne zu bereinigen, bevor sie gelöscht wird. Das Hauptproblem ist, dass das Löschen einer SageMaker Studio App mehr als die maximale Laufzeit von 15 Minuten der Custom Resource Lambda Function in Anspruch nehmen kann. Die Implementierung einer Step Function, die regelmässig den Status der SageMaker Studio App prüft und auf die Löschung wartet, hilft nicht, da Cloud Formation WaitCondition keine Löschvorgänge unterstützt und daher nicht wartet, bis das Signal von der Custom Resource zurückkommt, bevor mit der Löschung fortgefahren wird.
Zwei Issues wurden im CloudFormation-Repository geöffnet:


