
Cloud Engineer, aus Ostermundigen
#knowledgesharing #level 300
Vollautomatisierte MLOps-Pipeline - Teil 1
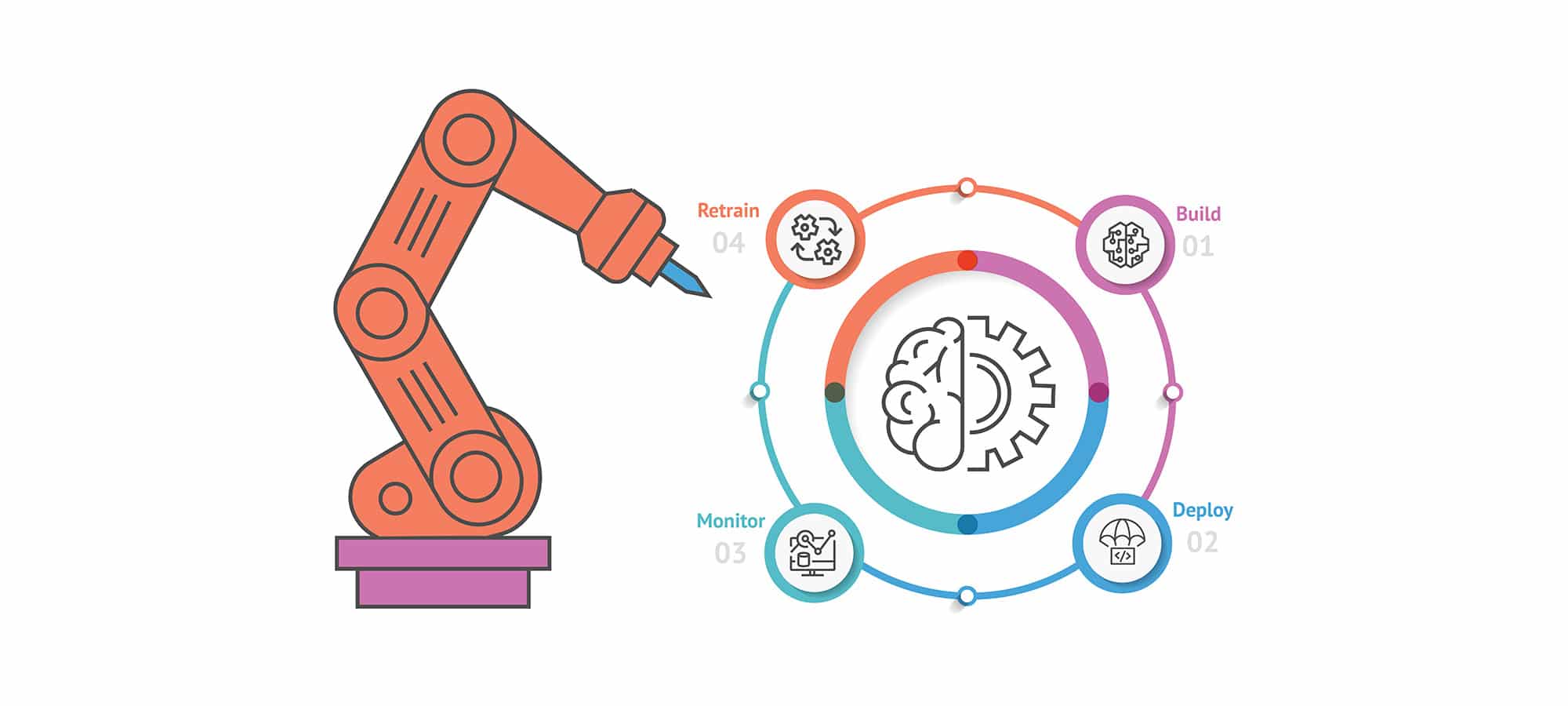
Das Ziel
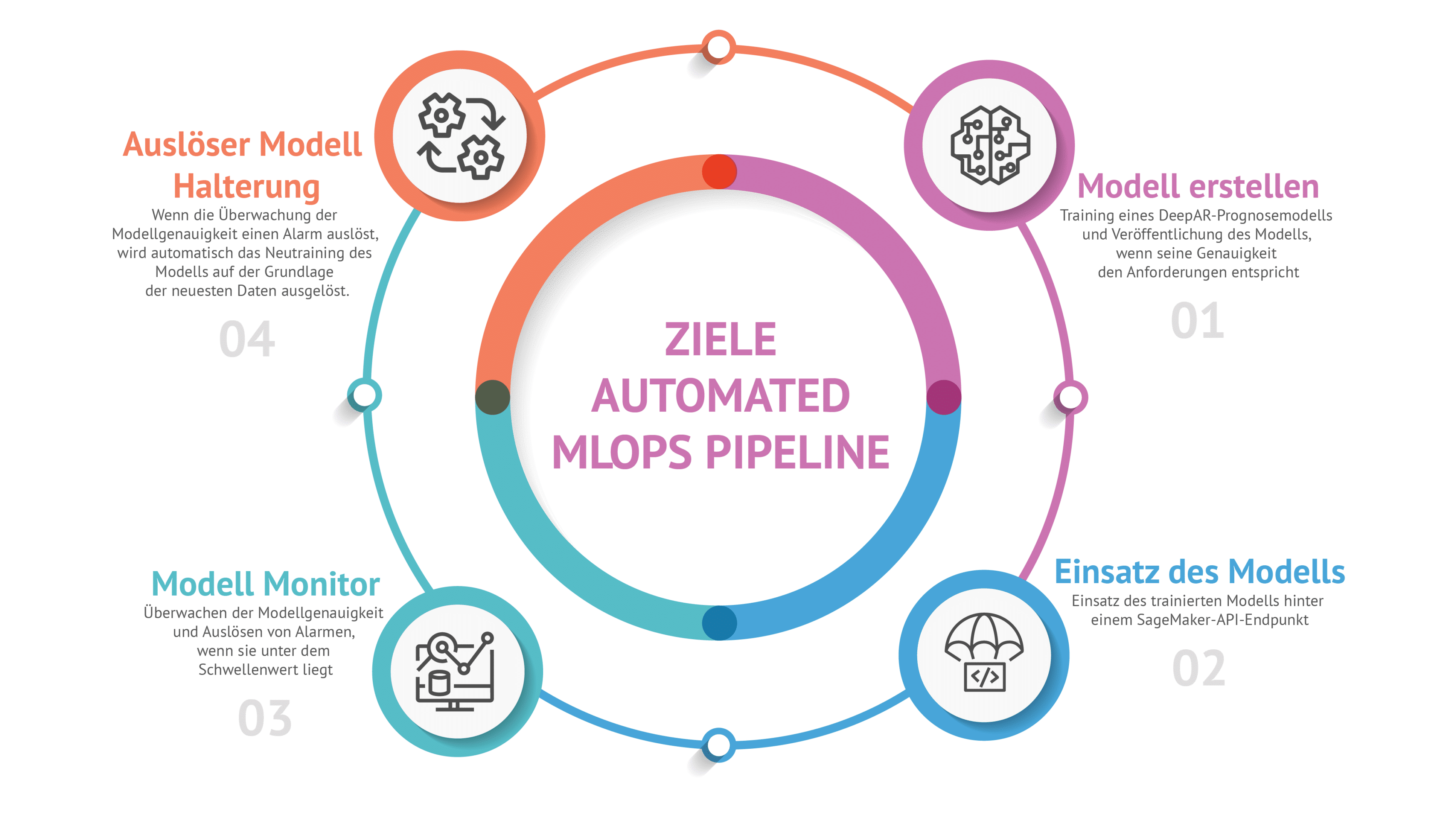
Das Model
Da die Dateneingabe-Pipeline die Blockchain Transaktion Metriken in Fast-Echtzeit im den Amazon SageMaker Feature Store aggregiert, haben wir uns für eine Prognose der durchschnittlichen Transaktionsgebühr entschieden.
Um ein Prognosemodell zu trainieren, haben wir den Amazon DeepAR-Prognosenalgorithmus gewählt. Dieser Algorithmus eignet sich besser für eindimensionale Mehrzeitreihen (z. B. den Energieverbrauch mehrerer Haushalte). In unserem Fall haben wir jedoch eine eindimensionale (durchschnittliche Transaktionsgebühr) Einzelzeitreihe (ein Zustrom von Blockchain-Transaktionen). Gemäss der AWS-Dokumentation kann DeepAR jedoch auch für Einzelzeitreihen verwendet werden. Bei dem von uns durchgeführten Schnelltest hat dieses Modell am besten abgeschnitten.
Wichtig zu wissen ist auch, dass das Hauptziel dieser Demo - nicht - darin besteht, das genaueste Modell zu trainieren. Wir brauchen das Modell nur, um einen vollautomatisierten MLOps-Lebenszyklus zu testen und die Verwendung eines vorgefertigten AWS-Modells hat die Entwicklung der Demo und unserer Pipeline erheblich vereinfacht.
Das Modell wurde darauf trainiert, die nächsten 30 durchschnittlichen Transaktionsgebühren vorherzusagen. Da wir Daten pro Minute aggregieren, prognostiziert es somit die durchschnittliche Transaktionsgebühr der Blockchain 30 Minuten in der Zukunft.
Um die Genauigkeit des Modells zu bewerten, wird in dieser Demo der Mean-Quantile-Loss-Metric verwendet.
Die Architektur
Die Architektur der Fast-Echtzeit Dateneingabe Pipeline findest du in einem vorherigen Blogbeitrag hier . Die aktuelle Architektur abstrahiert die Dateneingabe-Pipeline und konzentriert sich auf die MLOps-Architektur zum Trainieren und Betreiben des Modells.
Die Architektur basiert auf dem von AWS bereitgestellten SageMaker-Projekt für MLOps (bereitgestellt über den AWS Service Catalog), das wir an unser Projekt angepasst haben. Das SageMaker-Projekt bietet die folgendes:
- Ein AWS CodeCommit-Repository und eine AWS CodePipepline-Pipeline für
a. Model Build
b. Model Deploy
c. Model Monitor - Ein Amazon S3 Bucket zum Speichern aller Artefakte, die während des MLOps-Lebenszyklus erzeugt wurden.
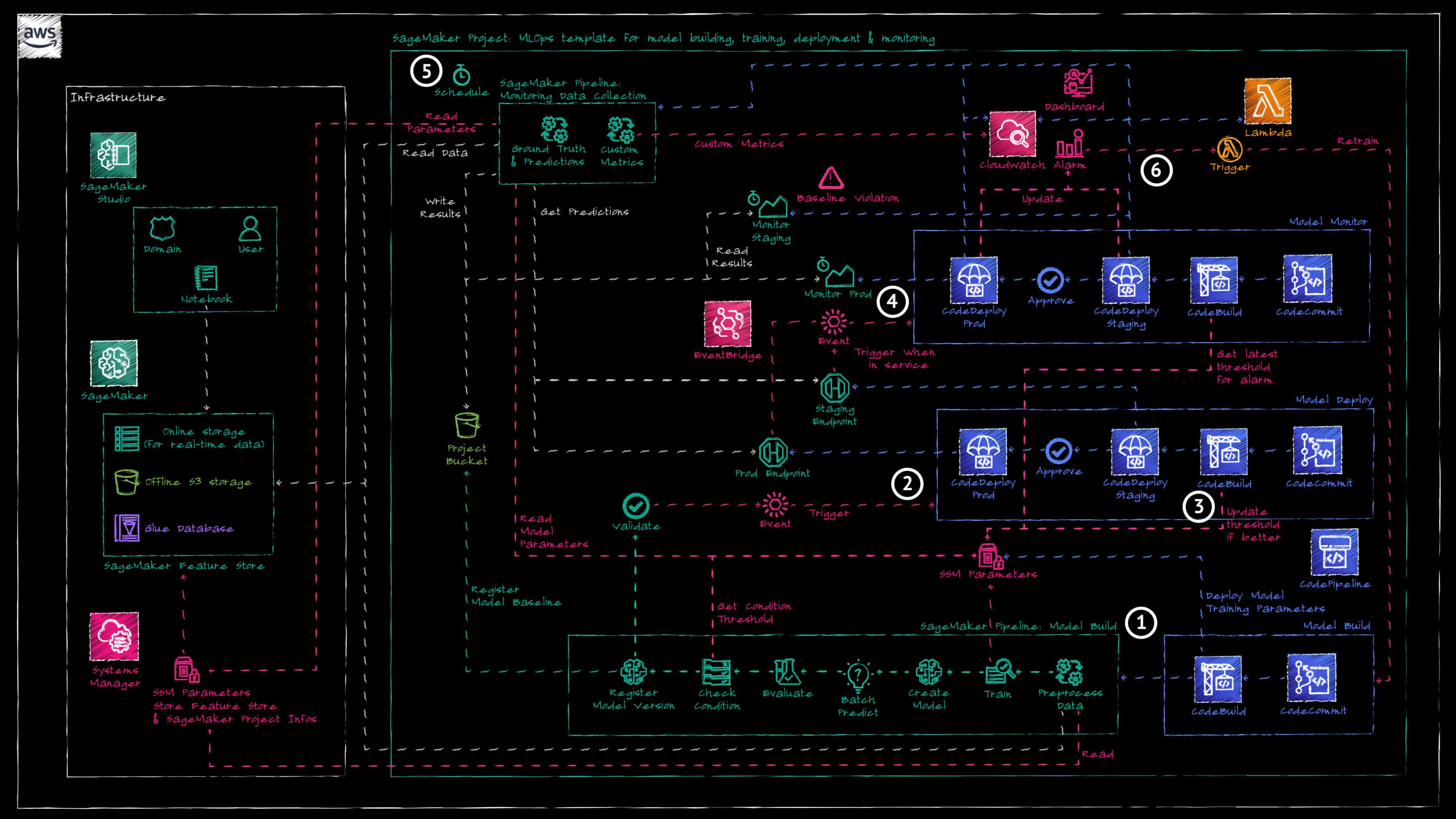
- Das «Model Build»-Verzeichnis und die Pipeline erstellen eine SageMaker-Pipeline zum Trainieren des Prognosemodells. Die Aufbau-Phase dieser Pipeline erstellt auch SSM-Parameter (falls nicht bereits vorhanden) mit den Hyperparametern für das Modelltraining und den Angaben für die Bewertung der Modellgenauigkeit.
- Die manuelle Freigabe des trainierten Modells löst automatisch die «Model Deploy»-Pipeline aus.
- Die «Model Deploy»-Pipeline stellt das Modell in der Staging-Umgebung (und später in der Produktionsumgebung, falls genehmigt) hinter einem Amazon SageMaker API-Endpunkt bereit.
- Sobald der Endpunkt in Betrieb ist, löst dies automatisch die Pipeline «Model Monitoring» zur Überwachung des neuen Modells aus.
- In einem stündlichen Zeitplan wird eine zusätzliche SageMaker-Pipeline ausgelöst, um die Prognoseergebnisse des Modells mit den neuesten Datenpunkten zu vergleichen.
- Fällt die Vorhersagegenauigkeit des Modells unter den akzeptablen Schwellenwert, wird die Pipeline «Model Build» erneut ausgelöst, um ein neues Modell auf der Grundlage der neuesten Daten zu trainieren.
Die zweite Hälfte dieser Architektur wird in einem weiteren Blogbeitrag beschrieben.
Erstellen des Modells mit der Sagemaker-Pipline
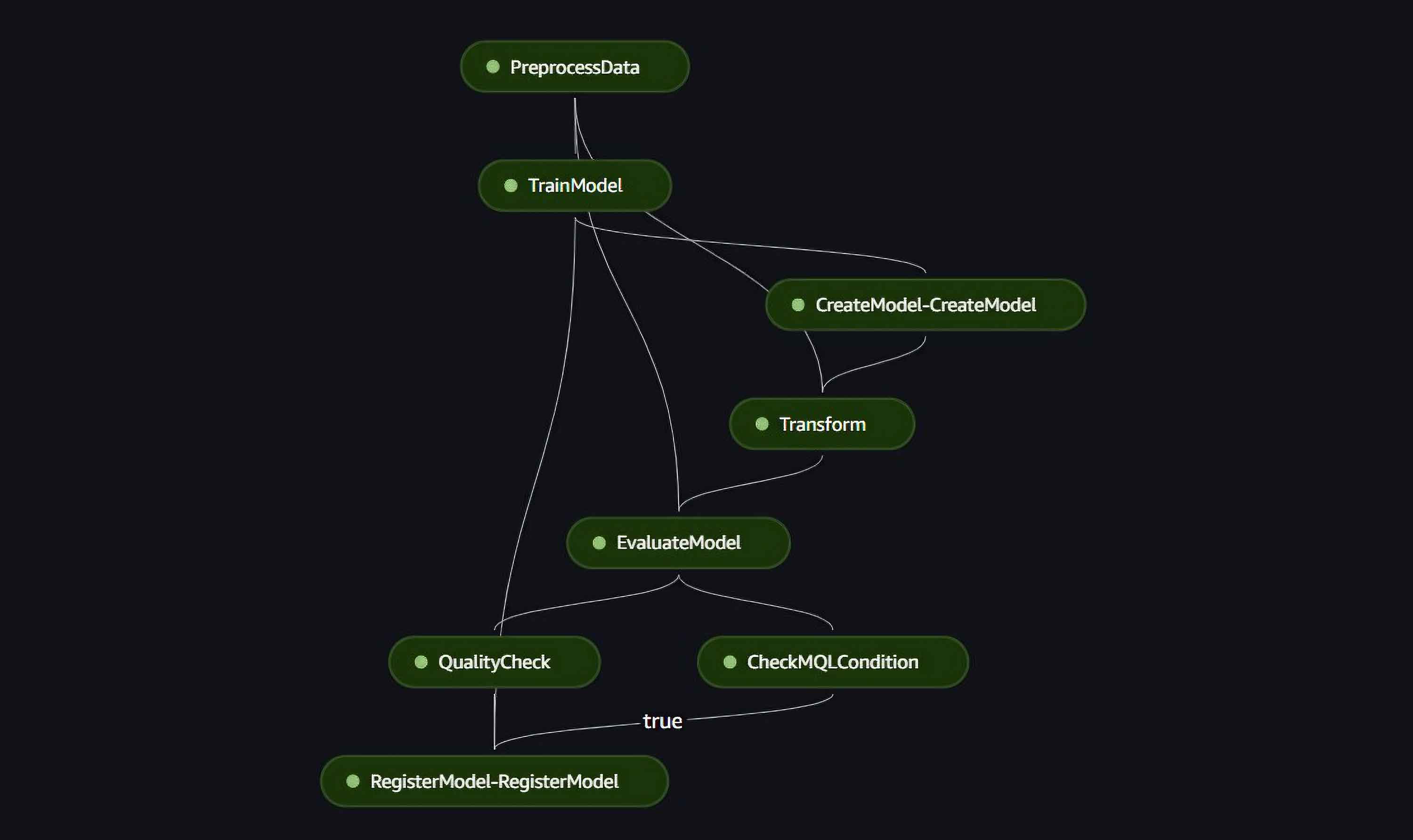
Das SageMaker-Projekt wird mit einem integrierten SageMaker-Pipeline-Code geliefert, welchen wir für unseren Anwendungsfall umgestalten mussten. Unsere Pipeline besteht aus den folgenden Schritten:
- Auslesen der Daten aus dem SageMaker-Feature-Store, Extrahieren der letzten 30 Datenpunkte als Testdatensatz zur Bewertung des Modells und Formatieren der Daten für den DeepAR-Algorithmus.
- Trainieren des Modells.
- Erstellung des trainierten Modells.
- Erstellung einer Stapelvorhersage für die nächsten 30 Datenpunkte auf der Grundlage der Trainingsdaten.
- Bewertung der Vorhersagegenauigkeit durch Berechnung des mean quantile loss zwischen den Vorhersage- und Testdatenpunkten.
- Überprüfung der Modellgenauigkeit im Vergleich zum Schwellenwert, der im SSM-Parameter gespeichert ist (wurde von der «Model Build»-Pipeline bereitgestellt).
- Registrierung des trainierten Modells, wenn seine Genauigkeit höher ist als der Schwellenwert.
Bereitstellung des Modells
Sobald das Modell in SageMaker registriert ist, muss es manuell genehmigt werden, damit es in der Staging-Umgebung ausgerollt wird. Die Freigabe des Modells löst automatisch die «Model Deploy»-Pipeline aus. Diese Pipeline führt 3 Hauptaktionen durch.
- Nach der Genehmigung des Modells wird die neue Modellgenauigkeit als neuer Schwellenwert verwendet - wenn dieser besser ist (ein niedrigerer Wert ist für unsere Metrik besser) als der bestehende - und damit der SSM-Parameter aktualisiert. In einem anderen Anwendungsfall möchtest du das vielleicht nicht tun, da es eine feste geschäftliche/gesetzliche Metrik gibt, die du erfüllen musst. Für diese Demo haben wir uns jedoch dafür entschieden, die Modellgenauigkeit zu aktualisieren, wenn neue Modelle trainiert werden, und so hoffentlich im Laufe der Zeit immer genauere Modelle zu erstellen.
- Eine erste AWS CodeDeploy-Phase stellt das neue Modell hinter einem Amazon SageMaker-Endpunkt zur Verfügung, der dann zur Vorhersage von 30 Datenpunkten in der Zukunft verwendet werden kann.
- Sobald das Modell hinter dem Staging-Endpunkt bereitgestellt wurde, wartet die Pipeline auf eine manuelle Genehmigung, bevor das neue Modell in der Produktion ausgerollt wird. Sobald es genehmigt wurde, wird das neue Modell in einer zweiten AWS CodeDeploy-Phase hinter einem zweiten Amazon SageMaker-Endpunkt für die Produktion zur Verfügung gestellt.
Die Herausforderungen
Die Verwendung des SageMaker-Projekts, das über den AWS Service Catalog bereitgestellt wird, war eine grosse Hilfe beim schnellen Aufbau des Gesamtrahmens für unsere vollautomatische MLOps-Pipeline. Allerdings gibt es eine Einschränkung: Die Pipelines für die Modellerstellung, -bereitstellung und -überwachung sind durch dieses AWS Service Catalog-Produkt festgelegt und passen möglicherweise nicht zu den Anforderungen. In unserer Demo verwenden wir zum Beispiel die CodeBuild-Phase der verschiedenen Pipelines, um den in den SSM-Parametern gespeicherten Schwellenwert für die Modellgenauigkeit festzulegen und zu aktualisieren (Build-Phase der «Model Deploy»-Pipeline) oder wir lesen aus um die Alarm Metriken zu erstellen. Dies ist nicht unbedingt die beste Art und Weise dies zu tun, aber es war die beste Lösung, die wir angesichts des festen Rahmens gefunden haben.
Wie bei jedem integrierten Framework kann man Zeit sparen und schneller vorankommen, indem man von einer vorgefertigten Lösung profitiert, aber verliert dann an der Flexibilität.


