
Cloud Engineer

Cloud Engineer
#knowledgesharing #level 300
Vollautomatisierte MLOps-Pipeline - Teil 2
Das Ziel
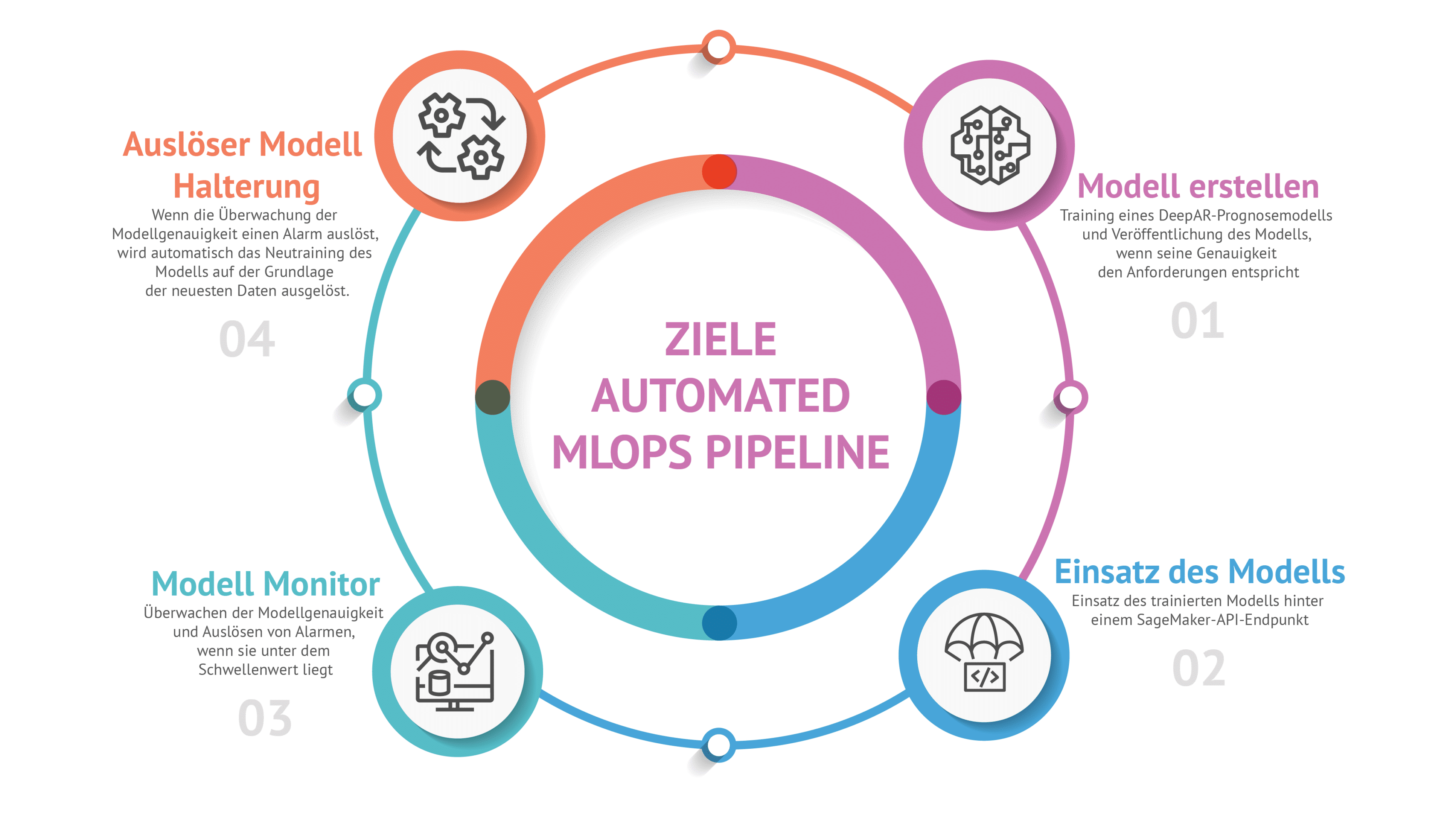
Das Model und die Architektur
Modell Überwachung
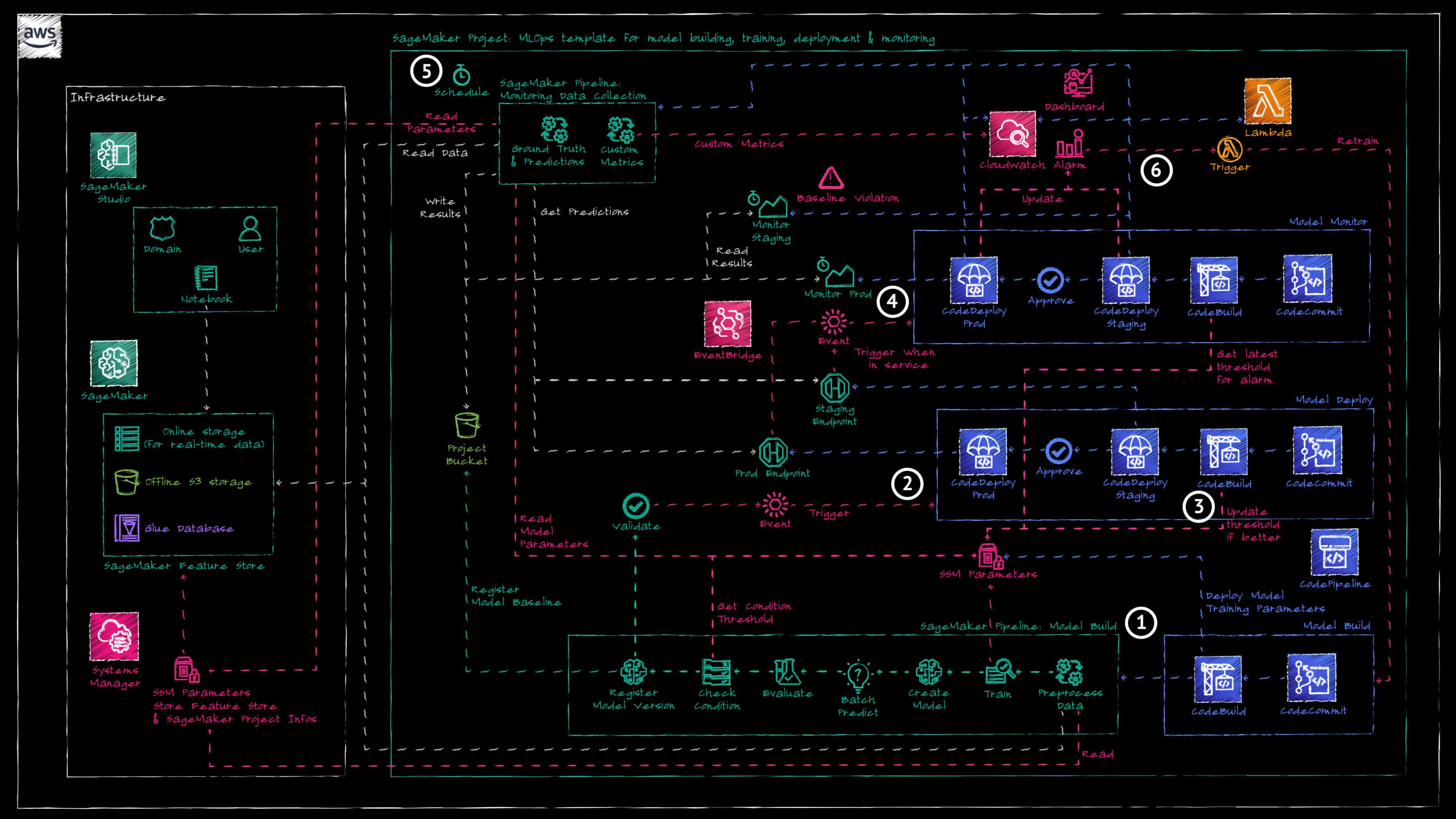
Die AWS CodePipeline zum Bereitstellen von Überwachungsressourcen wird automatisch ausgelöst, sobald der SageMaker-Endpunkt in den Zustand "IN_SERVICE" übergeht (Referenz 4).
SageMaker bietet integrierte Modellüberwachungsfunktionen, die von unserem Framework genutzt werden. Es gibt vier verschiedene Überwachungstypen, welche aktiviert und konfiguriert werden können: Datenqualität, Modellqualität, Modell Erklärbarkeit und Modell Verzerrung (Bias).
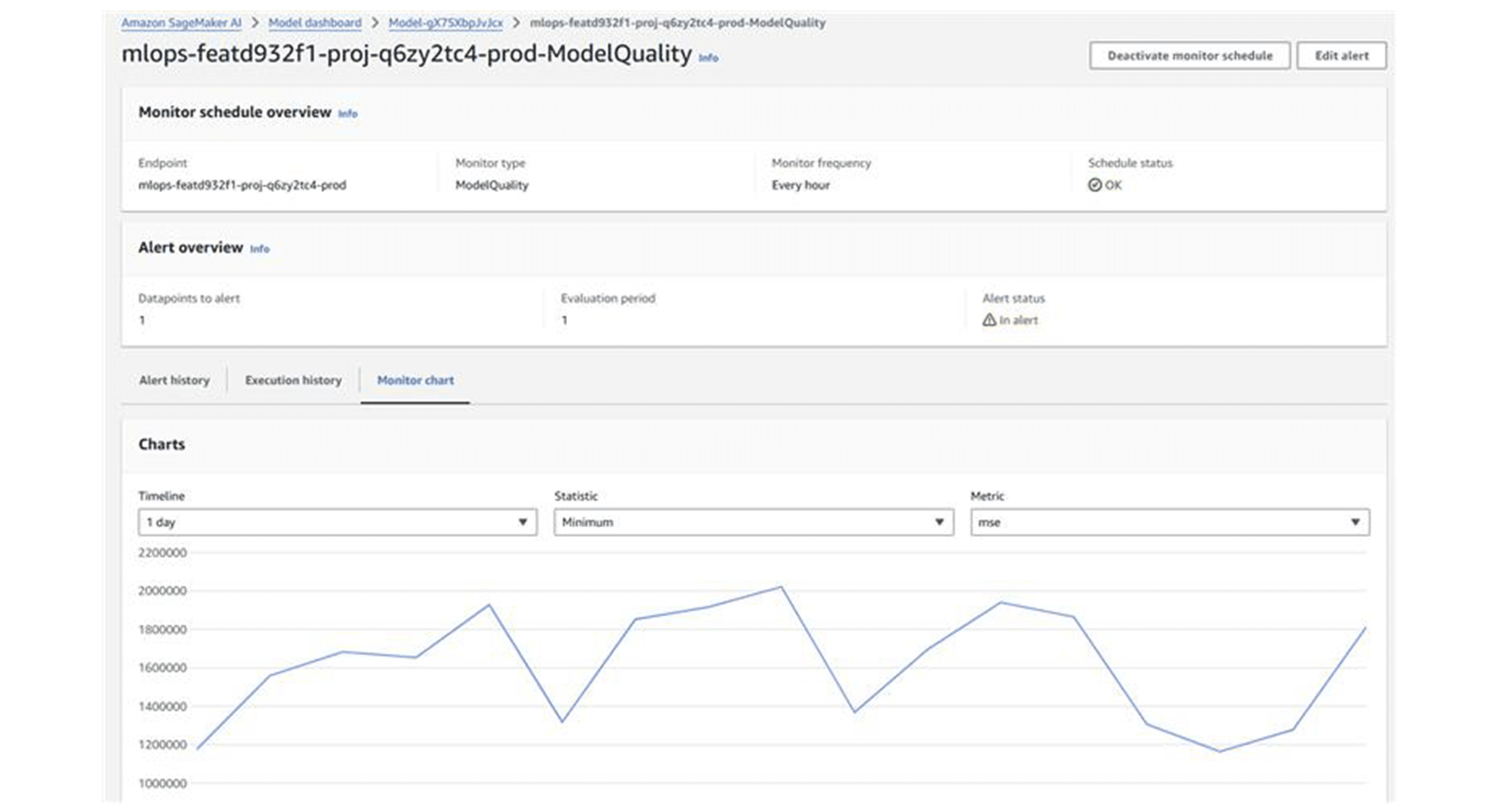
In dieser Demonstration verwenden wir nur die Überwachung der Modellqualität (siehe AWS-Dokumentation), welche aus zwei SageMaker-Verarbeitungsjobs besteht (Referenz 5):
- Ground Truth Merge: Dieser Job kombiniert Vorhersagen aus Echtzeit- oder Batch-Inferenz mit den tatsächlich in einem S3-Bucket gespeicherten Werten. Er verwendet die Ereignis-ID, um Ground-Truth-Datenpunkte mit den entsprechenden Vorhersagen abzugleichen, und gibt die resultierende Datei in den S3-Bucket des SageMaker-Projekts aus.
- Model Quality Monitoring: Dieser zweite Job verwendet die Ausgabedatei des Ground Truth Merge-Jobs, um Genauigkeitsmetriken basierend auf dem definierten Problemtyp (Regression, binäre Klassifikation oder Mehrklassen) zu berechnen. Diese Metriken werden dann mit dem in der während des Modelltrainings von der SageMaker-Pipeline generierten Einschränkungs-Datei definierten Schwellenwert verglichen.
Das SageMaker-Modell-Dashboard bietet Einblick in alle Überwachungsjobs und deren Ergebnisse.
Einschränkungen

- Für tabellarische Datensätze gemacht: Der Datensatz für die integrierte Überwachung muss einem expliziten Format entsprechen. Um dies zu umgehen, haben wir eine benutzerdefinierte SageMaker-Pipeline namens „Datensammlung“ erstellt. Diese führt ein Python-Skript vor dem Modellüberwachungszeitplan aus, um unseren Zeitreihendatensatz an dem korrekten Format anzupassen. Diese zusätzliche Pipeline ist in die Überwachungspipeline integriert und wird als Teil dieser auch zur Verfügung gestellt.
- Keine benutzerdefinierten Metriken: Die integrierte Überwachung erlaubt nur eine Handvoll Metriken zur Berechnung der Modellgenauigkeit für tabellarische Datensätze. In unserem Anwendungsfall der Zeitreihen mussten wir eine andere Metrik verwenden, um festzustellen, ob das Modell noch gut funktioniert oder ob es nachgeschult werden muss. Wir haben einen zusätzlichen Schritt in unsere „Datensammlung“-SageMaker-Pipeline eingefügt, welcher ein weiteres Python-Skript zur Berechnung der benutzerdefinierten Metrik ausführt. Das Ergebnis wird dann an eine benutzerdefinierte CloudWatch-Metrik gesendet, sodass es von anderen AWS-Diensten später ausgelesen werden kann.
- Zeitgesteuert ausgelöst: Es ist nicht möglich, die integrierte Überwachung ausserhalb des CRON-Zeitplans auszuführen. Dies macht es schwierig, diese vor oder nach anderen Jobs zu verknüpfen und damit Automatisierungen aufzubauen.
- Alarme generieren keine Ereignisse: Die Alarme im SageMaker-Modellüberwachungs-Dashboard generieren keine echten AWS-Ereignisse. Dies macht es unmöglich zum Beispiel auf schlechte Modellgenauigkeitsergebnisse zu reagieren indem danach automatische Prozesse ausgelöst werden. Da wir bereits die benutzerdefinierte CloudWatch-Metrik eingerichtet hatten, fügten wir einen CloudWatch-Alarm hinzu. Dieser Alarm prüft die Metrik gegen einen Schwellenwert und macht es möglich, die Modell Re-Training je nach dem automatisch auszulösen.
Modell Re-training
Eines der Hauptziele unserer MLOps-Pipeline war es, eine automatische Modell Re-Training zu ermöglichen, sobald die Modellgenauigkeit unter einen vordefinierten Schwellenwert fällt. Da AWS SageMaker keine integrierte Lösung für diesen Prozess bietet, haben wir die folgende benutzerdefinierte Lösung entwickelt:
- Überwachung: Wie oben beschrieben, haben wir eine Kombination aus einem SageMaker-Pipeline-Job verwendet, der eine benutzerdefinierte Metrik berechnet und als benutzerdefinierte CloudWatch-Metrik übermittelt, sowie einen CloudWatch-Alarm.
- Lambda-Funktion: Eine Lambda-Funktion wird durch einen CloudWatch-Alarm ausgelöst, wenn die Modellgenauigkeit unter den Schwellenwert fällt. Diese Funktion initiiert den gesamten MLOps-Lebenszyklus. Während der ersten "Model Build"-Phase wird das Modell erneut trainiert. Nach dem Re-Training können die Metriken validiert werden, und wenn die neue Modellversion besser abschneidet als die vorherige, kann sie manuell akzeptiert und ausgerollt werden.
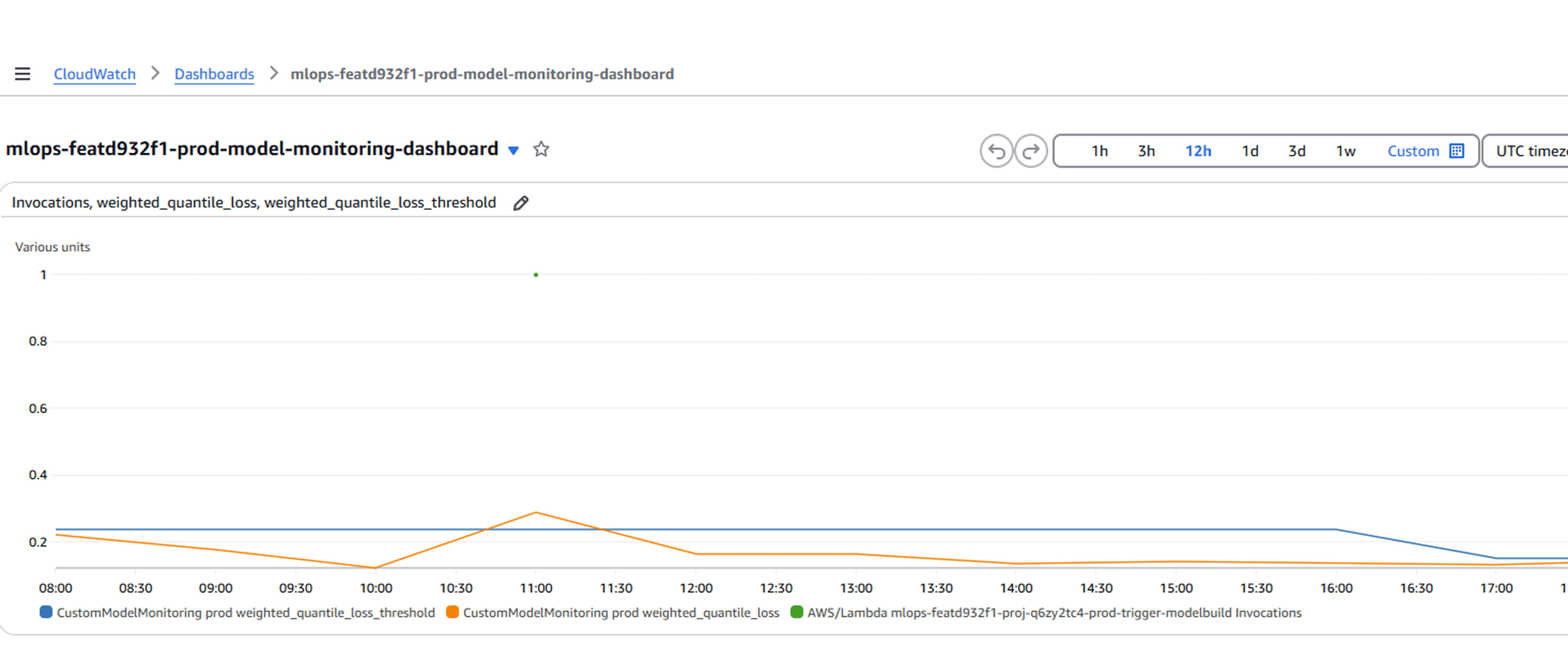
- CloudWatch-Dashboard: Ein benutzerdefiniertes CloudWatch-Dashboard wurde eingerichtet, um den aktuellen Schwellenwert (blau), die Modellgenauigkeitsmetrik (orange) und die Zeitpunkte, zu welchen die Lambda-Funktion zur Modell Re-Training ausgeführt wurde (grüne Punkte).
Fazit und Erkenntnisse

- Experiment vs. Betrieb: Eine wichtige Erkenntnis ist die Bedeutung des Übergangs vom Experiment zum eigentlichen Betrieb. Das Plattformteam muss sicherstellen, dass eine robuste Data-Science-Plattform für Experimente verfügbar ist. Sobald die Experimentierphase jedoch abgeschlossen ist, müssen die Daten-Ingenieure ihre Labor -Umgebung verlassen und ihren Code operationalisieren.
- Funktionsreiche Dienstleistung: AWS SageMaker erweist sich als leistungsstarkes Werkzeug, das eine Vielzahl von Funktionen für sowohl Data-Science-Experimente als auch die Operationalisierung bietet. Sein umfassendes Paket hilft, den Workflow von der Entwicklung bis zur Bereitstellung zu optimieren, was es zu einem wertvollen Werkzeug für Data-Science-Teams macht.
- Überwachungsbeschränkungen: Die integrierte Überwachung von SageMaker hat einige Einschränkungen. Sie ist hauptsächlich für tabellarische Datensätze konzipiert und bietet nur klassische Genauigkeitsmetriken. Darüber hinaus generiert das Alarmsystem keine Ereignisse, was ein Nachteil für Teams ist, welche dynamische Überwachungslösungen benötigen.
- Viel mehr zu entdecken: Unsere Experimente mit SageMaker haben gezeigt, dass es noch viel mehr zu entdecken gibt. Die Plattform bietet zusätzliche Überwachungsfunktionen wie Datenqualität und Datendrift-Erkennung, die wir noch untersuchen müssen. Diese Werkzeuge könnten tiefere Einblicke und bessere Kontrolle über die Modellleistung in der Produktion bieten.
Zusammenfassend erfordert eine erfolgreiche Navigation durch den Data-Science-Lebenszyklus eine sorgfältige Berücksichtigung sowohl der Experimentier- als auch der Betriebsphasen. Die Nutzung der umfangreichen Funktionen von Plattformen wie SageMaker, bei gleichzeitiger Berücksichtigung ihrer Einschränkungen, kann die Effektivität und Effizienz von Data-Science-Projekten erheblich steigern.



