
Cloud Engineer, from Ostermundigen
#knowledgesharing #level 300
Fully Automated MLOps Pipeline – Part 1
The Objective
The Model
As the ingestion pipeline aggregates in near real time blockchain transaction metrics into Amazon SageMaker Feature Store, we chose to forecast the average transaction fee.
In order to train a forecasting model, we decided to use Amazon DeepAR Forecasting Algorithm. That algorithm is better suited for one-dimensional multi time series (e.g. energy consumption of multiple households). However, in our case we have a one-dimensional (average transaction fee) single time series (one stream of blockchain transactions). But as per AWS documentation, DeepAR can still be used for single time series, and based on the quick test we performed, it is the model that was performing the best.
More importantly, the main objective of this demo is – not – to train the most accurate model. We just need – a – model to experiment a fully automated MLOps lifecycle and using a prepackaged AWS model, greatly simplified our pipeline and demo development.
The model is trained to forecast the next 30 average transaction fees. As we aggregate data per minute, it forecasts average transaction fee on the blockchain 30 minutes in the future.
To evaluate the accuracy of the model, this demo uses the mean quantile loss metric.
The Architecture
To see the near real time data ingestion pipeline architecture please refer to the previous blog post here. This architecture abstracts the data ingestion pipeline to focus on the MLOps architecture to train and operate the model.
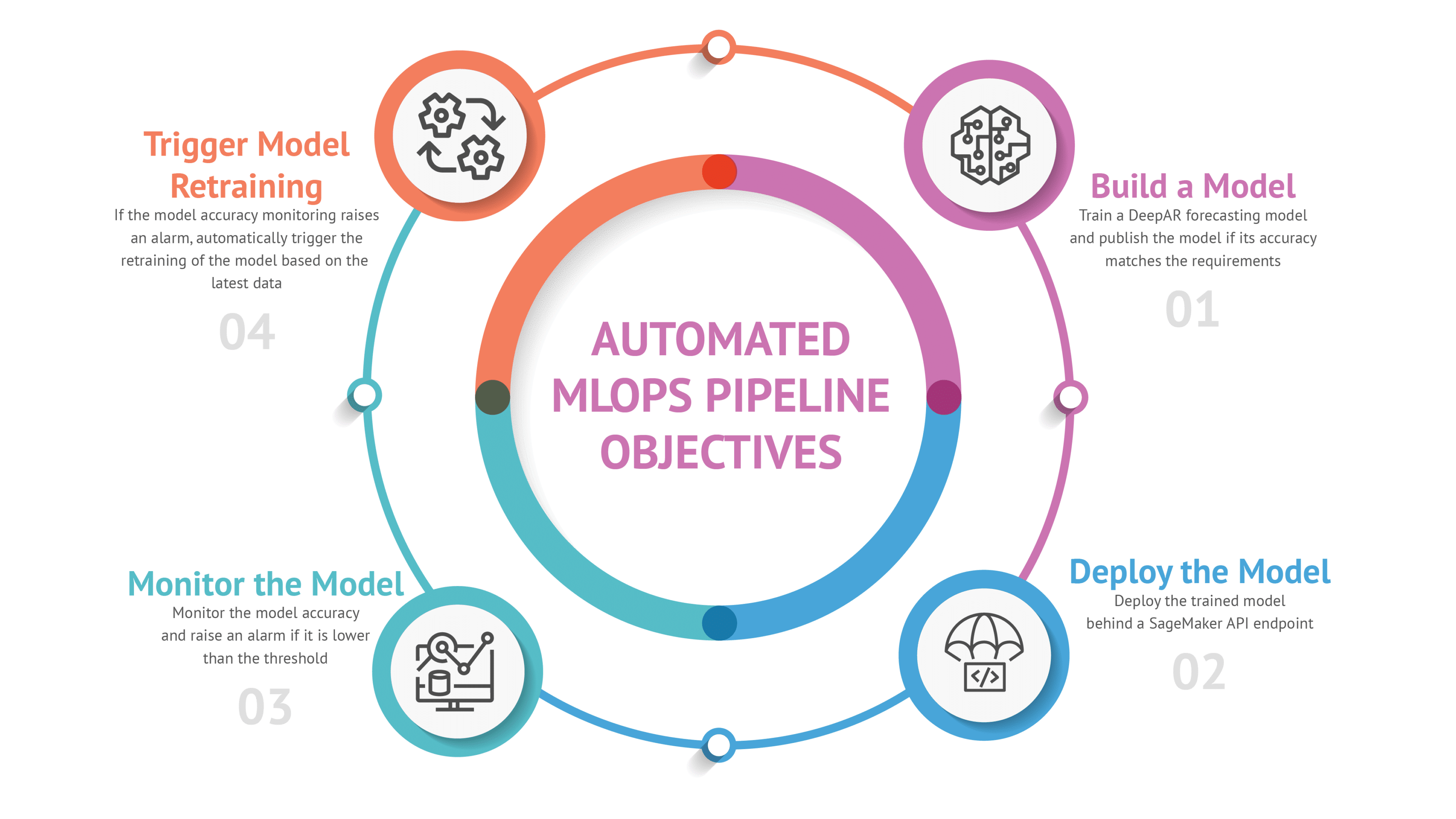
The architecture is based on AWS provided SageMaker project for MLOps (provisioned through AWS Service Catalog) which we adapted to our project. The SageMaker project provides the following:
- An AWS CodeCommit repository and AWS CodePipepline pipeline for
a. model building
b. model deployment
c. model monitoring - An Amazon S3 Bucket to store all the artifacts generated during the MLOps lifecycle.
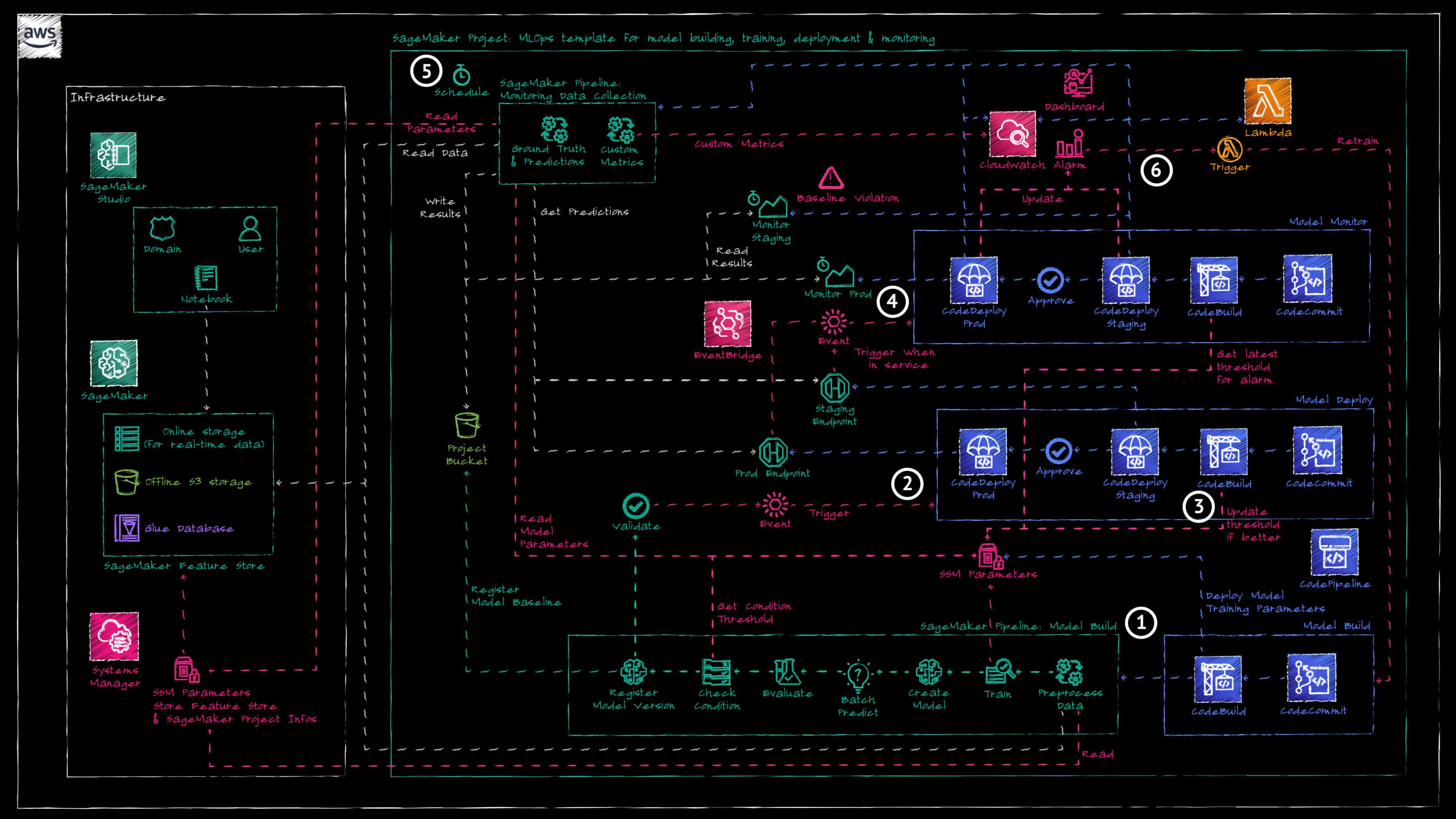
- The “Model Build” repository and pipeline deploy a SageMaker pipeline to train the forecasting model. The build phase of that pipeline also creates SSM Parameters (if they do not exist) holding the hyperparameters for the model training and to evaluate the model accuracy.
- The manual approval of a trained model automatically triggers the “Model Deploy” pipeline.
- The “Model Deploy” pipeline deploys in the staging environment (and later on in the production environment if approved) of the model behind an Amazon SageMaker API Endpoint.
- Once the endpoint is in service, this automatically triggers the deployment of the “Model Monitoring” pipeline to monitor the new model.
- On an hourly schedule, another SageMaker pipeline is triggered to compare the model forecast results with the latest datapoints.
- If the model forecasting accuracy falls under the acceptable threshold, the “Model Build” pipeline is automatically retriggered, to train a new model based on the latest data.
Building the model with the Sagemaker Pipeline
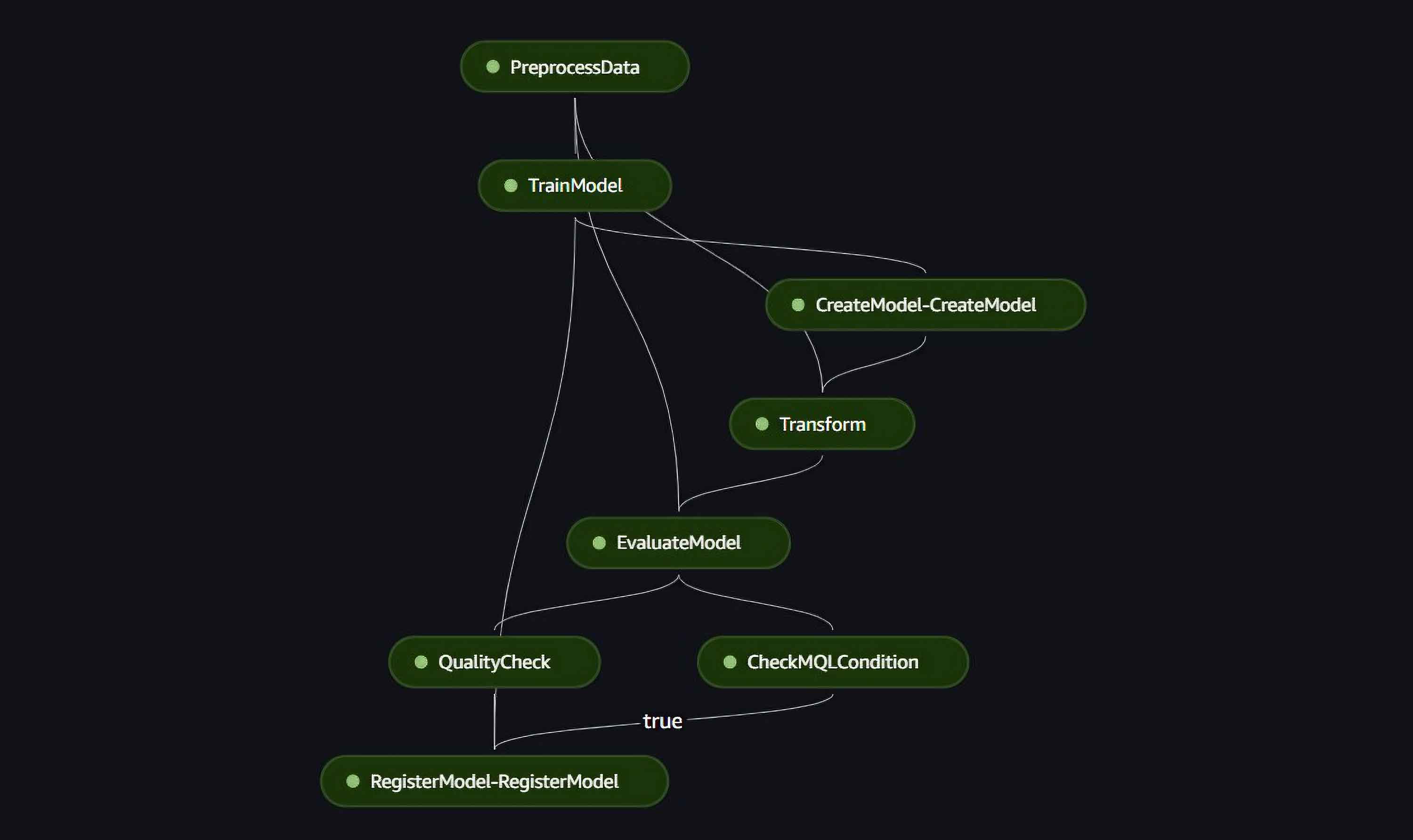
The SageMaker project comes with a built-in SageMaker pipeline code which we had to refactor to match our use case. Our pipeline consists of the following steps:
- Read the data from SageMaker Feature store, extract the last 30 data point as a test dataset to evaluate the model and format the data for the DeepAR algorithm.
- Train the model.
- Create the trained model.
- Make a batch prediction of the next 30 data points based on training data.
- Evaluate the forecast accuracy by computing the model’s mean quantile loss between the forecast and test datapoints.
- Check the model accuracy compared to the threshold stored in the SSM parameter (deployed by the “Model Build” pipeline).
- Register the trained model if its accuracy passes the threshold.
Deploying the model
Once the model is registered in SageMaker, it must be manually approved in order to be deployed in the staging environment first. The approval of the model will automatically trigger the “Model Deploy” pipeline. This pipeline performs 3 main actions.
- As the model has been approved, we take this new model accuracy as the new model threshold – if it is better (lower is better for our metric) than the existing one – and update the SSM parameter. You might not want to do that for your use case, as you might have fixed business/legal metric that you must match. But for this demo we decided to update the model accuracy as new models are retrained, hopefully building an increasingly accurate models as time passes.
- A first AWS CodeDeploy stage deploys the new model behind an Amazon SageMaker endpoint which can then be used to predict 30 data points in the future.
- Once the model has been deployed behind the staging endpoint, the pipeline has a manual approval stage before deploying the new model in production. If approved, then a second AWS CodeDeploy stage deploys the new model behind a second Amazon SageMaker endpoint for production.
The Challenges
The use of the SageMaker Project provided through AWS Service Catalog, was of significant help to quickly build the overall framework for our fully automated MLOps pipeline. However, it comes with a constraint: the model build, deploy and monitor pipelines are fixed by that AWS Service Catalog product and might not exactly fit your need. In this demo for example, in order to set and update the model accuracy threshold stored in SSM parameters we use the CodeBuild phase of the different pipelines to update that threshold (Build phase of the “Model Deploy” pipeline) or read it to create the alarm metrics. This is not necessarily the best way and place to do that, but it is the best solution we found given that fixed framework.
As with every built-in framework, you can save time and move faster by benefiting from a pre-built solution, but you lose in flexibility.